
📊 Full opportunity report: Agentic Loop Failure Modes: A Production Taxonomy at the End of Year One on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
After one year of deploying agentic AI systems, researchers have developed a detailed taxonomy of failure modes. This framework helps engineers diagnose and address issues effectively, improving system reliability.
Researchers have established a detailed taxonomy of failure modes in production agentic AI systems after one year of deployment, providing a structured vocabulary for diagnosing and mitigating failures. This development addresses a critical need for operational clarity as organizations increasingly rely on complex agentic workflows.
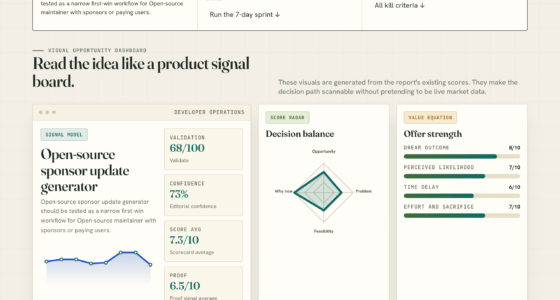
The taxonomy categorizes failures into six main groups with fifteen specific modes, including drift, coordination, termination, adversarial, tool interface, and state management failures. It maps each mode to detection difficulty, typical failure step, recovery cost, and architectural mitigation strategies.
Data from academic workshops at ICML 2026, as well as production reports like OpenClaw’s incident audits and AgentRx’s failure analyses, underpin this taxonomy. It aims to improve debugging efficiency and guide architectural improvements in real-world deployments.
Fifteen named failure modes.
First year of production agentic deployment is over. Year two is the structured-mitigation phase.
ICML 2026 has two dedicated workshops on the topic. Academic frameworks have arrived (Shahnovsky-Dror POMDP drift, Agent Drift study, AgentRx). Production reports have arrived (Agents of Chaos at OpenClaw, METR Task Complexity). The data is enough. The taxonomy is overdue. Six categories. Fifteen modes. Mapped to detection difficulty, production cost, mitigation maturity.
Six categories. Fifteen modes. Year one’s debugging vocabulary.
More granular taxonomies exist in the academic literature; they are useful for specific subdomains. For production engineering, the right granularity is the one a team can hold in working memory while debugging. Six categories is approximately that.

Power Failure Alert and Internet Outage Detector with Text Message and Email Notifications
Be alerted when either A/C power or Internet WiFi fails: get a text message, email or a push…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
A bad assumption at step 3 contaminates step 50. Surfaces at step 200.
Failures rarely break at the obvious moment. The agent demonstrates plausible behavior at every individual step — but the trajectory has drifted. By the time anyone notices, the originating cause is hundreds of steps in the past.

Agentic AI Systems for Developers: A Developer’s Guide for Designing, Debugging, and Scaling Production-Ready Multi-Agent Systems
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Six categories. Six different priorities.
Production agentic systems should optimize their engineering investment in order of return-on-engineering, not moral hierarchy. Tool interface first (high frequency, easy fix). Adversarial last (catastrophic but rare).
The teams that adopt the taxonomy, invest in the eval harness, and implement the architectural patterns will capture the reliability gap and the customer trust that comes with it. Year two is the structured-mitigation phase.

Enterprise AI Observability and Monitoring: Monitoring, Governing Production AI Systems Drift Detection, LLM Monitoring, Agentic AI, Governance, and FinOps … (Enterprise Machine Learning Operations)
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Four assignments. By role.
Build targeted probes for each named mode.
The eval-harness gap is the single largest unsolved problem for production agentic deployments. Build the targeting probes. Publish evaluation methodologies. The lab that produces a credible end-to-end agentic eval harness for the failure modes in this taxonomy captures durable strategic position. Current state of the art is fragmented; consolidation overdue.
Audit production systems against six categories.
For each: confirm whether targeted detection exists, whether the team can identify the originating step of a failure, whether mitigation patterns are in place. Most production systems have substantial gaps in state management, coordination, adversarial modes. Cost of remediation is high but lower than catastrophic incident cost.
Adopt the taxonomy as debugging vocabulary.
Library the failure-mode patterns. Implement at least the easy mitigations (tool interface, termination) before deploying. Invest in trajectory replay tooling early — debugging time savings alone justify engineering cost. Teams that systematically debug against the taxonomy ship more reliable agents than teams that don’t.
Submit to FMAI and FAGEN.
The field needs negative results, minimal reproductions, falsifiable mechanistic hypotheses. Current academic literature is heavy on framework proposals and light on operational definitions and minimal reproductions. The ICML 2026 workshops are explicitly soliciting both. Best Paper Awards available; non-archival venue allows dual submission.

UREVO Smart Leg Recovery PT Pro, AI-Powered Tech Rechargeable Air Compression Massager Boots for Circulation, Smart Pain Senser and Foot Muscle Recovery to Athletes After Summer Sports, Blue
✅【 Professional Air Compression for Deep Muscle Relief】- Experience precise physiotherapy with Recovery’s innovative matrix airbag system. Built…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Operational Impact of the Failure Taxonomy
This taxonomy provides engineers with a practical vocabulary and structured framework to identify, diagnose, and address failure modes in agentic AI systems. It supports targeted evaluation, reduces redundant troubleshooting efforts, and guides architectural design choices, ultimately enhancing system reliability and safety in production environments.
First Year of Production Agentic System Failures
Since the deployment of agentic AI systems began in late 2024, a growing body of failure data has emerged, revealing patterns and common issues. Academic workshops at ICML 2026 have formalized these insights into a taxonomy, building on prior studies like Shahnovsky and Dror’s POMDP drift formalization and AgentRx’s root-cause analysis. Production reports, including OpenClaw’s incident audits, have documented frequent failure modes, emphasizing the need for a structured diagnostic vocabulary.
“The first year of deployment has provided enough failure data to formalize a practical taxonomy that directly supports engineering teams in debugging and architecture.”
— Thorsten Meyer
Uncertainties in Failure Mode Detection and Mitigation
While the taxonomy maps failure modes to detection difficulty and mitigation strategies, real-world detection remains challenging for drift and coordination failures. The effectiveness of architectural responses varies, and some failure modes, especially adversarial ones, are still not well-understood or mitigated in practice. It is not yet clear how comprehensive or adaptable this taxonomy will be as deployments expand and evolve.
Next Steps in Operationalizing Failure Detection
Engineering teams will begin adopting this taxonomy for routine debugging and evaluation. Further research is expected to refine detection techniques, especially for drift and coordination failures. Additionally, organizations will likely develop automated monitoring tools aligned with these failure categories to improve real-time diagnosis and response.
Key Questions
How does this taxonomy improve debugging in production?
It provides a shared vocabulary and structured framework, enabling engineers to quickly identify failure modes, reuse mitigation strategies, and build institutional knowledge.
Are all failure modes equally detectable and mitigable?
No, some modes like drift and coordination failures are harder to detect and mitigate than tool interface failures, which are more straightforward but more common.
Will this taxonomy evolve with new failure data?
Yes, ongoing deployment and research will likely refine and expand the taxonomy to address emerging failure modes and improve detection and mitigation strategies.
How will organizations use this taxonomy practically?
Teams will incorporate it into debugging workflows, targeted evaluations, architectural planning, and automated monitoring systems to enhance reliability.
Source: ThorstenMeyerAI.com