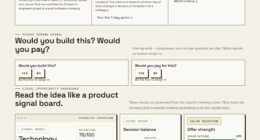

📊 Full opportunity report: Data: The One Thing You Can’t Rent on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
The AI industry is shifting from renting compute to securing scarce, high-quality data. Legal battles and licensing mark the end of free scraping, making data ownership a critical survival strategy for AI labs.
In 2026, the AI industry has effectively declared that data is the one resource you cannot rent or freely acquire anymore. This shift follows legal and market changes that have made data ownership and licensing essential, marking a new chokepoint in AI development and competition.
Recent legal settlements, such as Anthropic’s $1.5 billion copyright agreement, confirm that the era of free web scraping for training data is over. Instead, companies are now facing a market where data must be licensed, purchased, or fenced behind legal and financial barriers.
Industry insiders note that the remaining high-value data is increasingly located behind paywalls, within enterprise systems, or in the expertise of specialists—making access more exclusive and expensive. Synthetic data, while a partial solution, carries risks of errors and model collapse if overused in domains requiring verification.
Furthermore, the move toward licensing and legal restrictions has favored large, resource-rich firms, creating barriers for startups and smaller labs. Learn more about AI industry trends and threats. This consolidation is reinforced by recent court rulings and high-profile industry disputes, signaling a fundamental shift in how data is acquired and protected in AI development.
Data: The One Thing You Can’t Rent
The free part of “all human knowledge” is running out. As compute and models commoditize, the corpus you can’t replicate becomes the moat — so data is being fenced, priced, and, in places, treated as a national asset.
Data was supposed to be the abundant input. It’s the scarce one. It’s also the chokepoint you can actually own — so guard your proprietary data, and don’t hand it to a provider who can become your competitor (the lesson everyone fled Scale to learn). Nations: license it like Ukraine — keep the model, keep the leverage.
Implications of Data Fencing for AI Industry Competition
This development means that data ownership has become a key strategic asset in AI, with legal and financial barriers preventing open access. It favors established companies with deep pockets, potentially reducing innovation diversity and increasing industry consolidation. For startups and smaller labs, access to high-quality, verified data now depends on licensing agreements, which can be prohibitively expensive.
Additionally, the emphasis on verified human-made data raises questions about the future of open data initiatives and the sustainability of AI training models relying on synthetic or unverified sources. The shift could reshape the competitive landscape, making data a primary chokepoint and a form of industry moat.

Crystal Pilot VFR and IFR Placard (Medium (4.5 x 7 inches))
STRONG AND WATERPROOF: 125 x 178 x 0.76 mm (same thickness as your credit card). 4.9 x 7…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Legal and Market Shifts Reshaping Data Access
Historically, AI training relied heavily on scraping freely available web data, with minimal legal risk. However, in 2026, landmark legal cases, such as Anthropic’s $1.5 billion settlement over copyright infringement, have set a precedent that scraping copyrighted material without permission is not protected by fair use.
This has led to a wave of licensing agreements between publishers, tech giants, and AI companies, transforming data from a free resource into a paid commodity. Industry leaders like Microsoft and Meta have invested heavily in acquiring exclusive, high-quality datasets, often involving expert-generated content.
Simultaneously, synthetic data is increasingly used to supplement training sets, but it cannot fully replace verified human-generated data due to accuracy concerns. The scarcity of accessible, high-quality data is now recognized as the defining chokepoint in AI progress.
“The court’s ruling clarifies that scraping copyrighted books without permission is not protected under fair use, setting a significant legal precedent.”
— Legal expert involved in Anthropic case

Statistics: Informed Decisions Using Data (5th Edition)-Stand alone
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Unclear Impact on Smaller Players and Future Data Markets
It remains unclear how smaller AI labs and startups will adapt to the rising costs and legal barriers associated with data licensing. The long-term effects of these legal rulings on open data initiatives and innovation diversity are still developing, and the full scope of industry consolidation is yet to be seen.
Synthetic Data Generation: A Beginner’s Guide
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Next Steps in Data Licensing and Industry Consolidation
Expect continued growth in licensing agreements between publishers and AI firms, alongside legal battles over data rights. Smaller labs may seek alternative strategies, such as synthetic data or proprietary data collection, but these approaches come with their own limitations. Industry consolidation is likely to accelerate, with large firms controlling most high-quality datasets, potentially impacting innovation and competition.

Validation, Verification, And Testing Of Computer Software, Issues 500-575
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
Why can’t data be rented like compute or power?
Unlike compute or power, data is a finite resource that depends on human effort, legal rights, and verification. It cannot be duplicated or leased at will without ownership or licensing agreements, especially when it involves copyrighted or sensitive information.
What are the legal implications of the Anthropic settlement?
The settlement confirms that scraping copyrighted works without permission is not protected under fair use, leading to increased licensing requirements and legal risks for data collection practices.
How will this shift affect AI innovation?
It could slow innovation among smaller players due to higher costs and legal barriers, while favoring large firms with resources to acquire or license high-quality data. The industry may also see increased reliance on synthetic or proprietary data sources.
Is open data or free scraping completely dead?
While legal restrictions have increased, some open data initiatives may continue, but their role in training cutting-edge models is likely to diminish as licensed and proprietary data become dominant.
What does this mean for the future of AI training?
The future will likely see a shift toward curated, licensed, and verified datasets, with less reliance on freely available web data. This could lead to higher costs and more industry concentration but potentially more reliable AI models.
Source: ThorstenMeyerAI.com